Handling errors
The error can occur at multiple places during development and usage of the parser. This chapter gives an overview of each class of errors and actions that can be taken to solve them.
The errors you can encounter with Rustemo are:
- Parser development errors:
- Syntax errors in the grammar
- Semantic errors in the grammar - invalid grammar (e.g. undefined symbol, infinite loop on a symbol)
- LR conflicts - non-deterministic grammar (these errors apply only for LR not for GLR)
- Parser usage errors:
- Syntax errors in the parsed input
When an error happens Rustemo tries to provide a detailed information of the problem. In the sections that follows an overview of each class is given.
Investigating grammar syntax errors
If your grammar is not written according to the Rustemo grammar language rules the Rustemo compiler will report an error with the information about the location and expected tokens at that location.
Here is an example of a grammar syntax error:
Error at json.rustemo:[3,7]:
...a] "}";
Member -->JsonString ":" ...
Expected one of Colon, OBrace.
The error report have a file and line/column location. You can also see the
context where the error occurred with --> mark at the position.
Investigating grammar semantic errors
A grammar may be syntactically correct but still semantically incorrect. For example, you may have a reference to undefined grammar symbol.
Here is an example of a semantic error:
Error at json.rustemo:[3,8-3,17]:
Unexisting symbol 'JsonStrin' in production '13: JsonStrin ":" Value'.
The location info contains the span where the symbol is specified in the grammar: from line 3 column 8 to line 3 column 17.
Resolving LR conflicts
Please see the chapter on parsing for the introduction to LR parsing.
LR parsing is based on a deterministic finite-state automata. Because the generated automaton must be deterministic there can be exactly one operation the parser can perform at each state and for each input token.
Not all context-free grammars produce a deterministic automaton. Those that do are called deterministic context-free grammars (DCFL) and they are a proper subset of context-free grammars (CFG).
LR parser generators can produce parsers only for DCFLs.
See this section for a generalized version of LR.
When there is a state in which multiple actions occur we have a conflict. Depending on the conflicting actions we may have:
- shift-reduce conflicts - where the parser could either shift the token ahead or reduce the top of the stack by some production,
- reduce-reduce conflicts - where the parser could reduce by two or more reductions for the given lookahead token.
In both cases Rustemo compiler produces a detailed information and it is a crucial to understand what is the problem and what you should do to make the grammar deterministic.
When a conflict arise we have a local ambiguity, i.e. Rustemo can't build a state in which the parser will know what to do by just looking at one token ahead. If the parser would know by looking at more tokens ahead than we have a local ambiguity, but if there are situations in which the parser couldn't decide with unlimited lookahead then our language is ambiguous which means that some inputs may have more than one interpretation.
Let's investigate a conflict on a famous if-then-else ambiguity problem. For
example, if we have this little grammar which describes a language of nested
if statements:
IfStatement: 'if' Condition 'then' Statements
| 'if' Condition 'then' Statements 'else' Statements;
Statements: Statements Statement | Statement | EMPTY;
Statement: IfStatement;
terminals
If: 'if';
Then: 'then';
Else: 'else';
Condition: 'cond';
Then running rcomp would reveal that we have 3 shift/reduce conflicts. Let's
investigate those conflicts one by one.
In State 6:Statements
IfStatement: If Condition Then Statements . {STOP, If, Else}
IfStatement: If Condition Then Statements . Else Statements {STOP, If, Else}
Statements: Statements . Statement {STOP, If, Else}
Statement: . IfStatement {STOP, If, Else}
IfStatement: . If Condition Then Statements {STOP, If, Else}
IfStatement: . If Condition Then Statements Else Statements {STOP, If, Else}
When I saw Statements and see token If ahead I can't decide should I shift or reduce by production:
IfStatement: If Condition Then Statements
This state is reached when the parser has seen Statements. The state is
described by so called LR items. These items are productions with a dot
marking the position inside the production where the parser may be. At the same
time, since the items are LR(1) (thus one lookahead), we have possible lookahead
tokens in curly braces for that production position.
The end of the report (starting with When I saw...) gives the explanation. In
this state, when there is If token as a lookahead, the parser can't determine
whether it should shift that token or reduce previously seen IfStatement.
To put it differently, the question is if the next If statement should be
nested inside the body of the previous If statement, in which case we should
shift, or in the body of some outer If statement, in which case we should
reduce previous statement and treat the next If as the statement on the same
nesting level.
The rest two conflicts are similar:
In State 6:Statements
IfStatement: If Condition Then Statements . {STOP, If, Else}
IfStatement: If Condition Then Statements . Else Statements {STOP, If, Else}
Statements: Statements . Statement {STOP, If, Else}
Statement: . IfStatement {STOP, If, Else}
IfStatement: . If Condition Then Statements {STOP, If, Else}
IfStatement: . If Condition Then Statements Else Statements {STOP, If, Else}
When I saw Statements and see token Else ahead I can't decide should I shift or reduce by production:
IfStatement: If Condition Then Statements
In State 10:Statements
IfStatement: If Condition Then Statements Else Statements . {STOP, If, Else}
Statements: Statements . Statement {STOP, If, Else}
Statement: . IfStatement {STOP, If, Else}
IfStatement: . If Condition Then Statements {STOP, If, Else}
IfStatement: . If Condition Then Statements Else Statements {STOP, If, Else}
When I saw Statements and see token If ahead I can't decide should I shift or reduce by production:
IfStatement: If Condition Then Statements Else Statements
Second is for the same state but different token ahead, else in this case. The
third is similar to the first.
All three conflicts are due to the parser not knowing how to nest statements. An if we think about it, with our language defined as it is currently, there is no way to decide how we should nest statements. For example:
if cond then if cond then else
Since the body of then and else branch may contain EMPTY the above example has empty body in the last then and else blocks.
The previous example could be interpreted as:
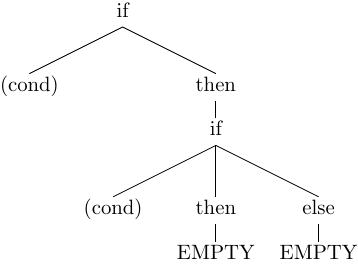
or
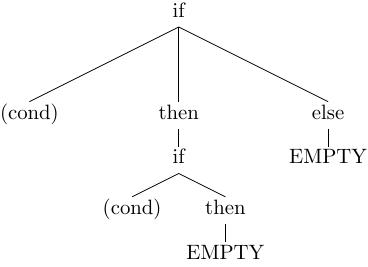
Thus, the else part can belong to the inner If statement as depicted in the
first tree, or to the outer statement as shown in the second tree.
In this case, our language is trully ambiguous and larger lookahead won't help.
There are two approaches to handle these conflicts:
- Add additional rules and use disambiguation techniques (priorities and associativities meta-data)
- Change the grammar/language to eliminate ambiguities
When deciding whether to create a shift or reduce operation for a state Rustemo
will look into priorities of terminals and productions and choose the one with
higher priority. If the priorities are the same Rustemo will look at
associativities, and favor the one set on terminal if not default (None).
So, in our case we could specify a greedy behavior for all three conflicts. This behavior means that we will favor shift operation thus always choosing to nest under the innermost statement.
IfStatement: 'if' Condition 'then' Statements
| 'if' Condition 'then' Statements 'else' Statements;
Statements: Statements Statement | Statement | EMPTY;
Statement: IfStatement;
terminals
If: 'if' {shift};
Then: 'then';
Else: 'else' {shift};
Condition: 'cond';
Now, the grammar will compile, as the only possible interpretation of the above example will be the first tree.
Sometimes it is better and more readable to specify associativity on the production level. See the calculator tutorial for example.
The other way to solve the issue is by changing our language. The confusion is
due to not knowing when the body of the If statement ends. We could add curly
braces to delineate the body of If like all C-like languages do, or simply add
keyword end at the end. Let's do the latter:
IfStatement: 'if' Condition 'then' Statements 'end'
| 'if' Condition 'then' Statements 'else' Statements 'end';
Statements: Statements Statement | Statement | EMPTY;
Statement: IfStatement;
terminals
If: 'if';
Then: 'then';
Else: 'else';
End: 'end';
Condition: 'cond';
Now, our language is more flexible as the user can define the nesting by placing
end keyword at appropriate places.
Global preference for resolving shift-reduce conflicts
One of the standard techniques to resolve shift/reduce conflicts is to prefer shift always which yields a greedy behavior.
This settings is available through rcomp CLI or Settings type API. By
default shift is not preferred. Furthermore, there is a separate control on the
preference of shift over empty reductions.
See the section on disambiguation meta-data in the grammar
Syntax errors in the parsed input
These are errors which you have to handle in your code as the user supplied an invalid input according to your grammar specification.
When you call parse/parse_file method with the input, you get a Result value
where Ok variant will hold the result produced by the configured builder,
while Err variant will hold information about the error.
For example, this can be a result of erroneous input where the result value is converted to a string:
Error at input2.calc:19(2,9):
Expected Number.
You can see the path of the input file, line/column location of the error, the
context where the error location is marked with -->, and finally the cause of
the error (Expected Number).
The parser is called like this:
#![allow(unused)] fn main() { let mut parser = CalculatorParser::new(); let result = parser.parse_file(local_file!(file!(), "input2.calc")); }
Error type contained in Err variant is defined as follows:
#![allow(unused)] fn main() { #[derive(Debug, thiserror::Error)] pub struct ParseError { pub message: String, // FIXME: This should be borrowed when error recovery is implemented. pub src: Option<String>, pub file: Option<String>, pub span: Option<SourceSpan>, } fn with_style(d: &impl Display, style: Style) -> String { d.paint(style).to_string() } impl Display for ParseError { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { let mut loc_str = String::from("Syntax error"); if self.file.is_some() || self.span.is_some() { loc_str.push_str(" at "); } if let Some(ref file) = self.file { loc_str.push_str(file); if self.span.is_some() { loc_str.push(':'); } } if let Some(span) = self.span { loc_str.push_str(&format!("{span:?}")); } if let (Some(src), Some(span)) = (self.src.as_ref(), self.span) { let idx = LineIndex::new(src); let mut prev_empty = false; let style = |style: Style| move |s| with_style(&s, style); let block = Block::new( &idx, [Label::new(span.start.pos..span.end.pos) .with_text(&self.message) .with_style(style(WARN))], ) .unwrap() .map_code(|s| { let sub = usize::from(core::mem::replace(&mut prev_empty, s.is_empty())); let s = s.replace('\t', " "); let w = unicode_width::UnicodeWidthStr::width(&*s); CodeWidth::new(s, core::cmp::max(w, 1) - sub) }); write!( f, "\n{} {}\n{block}{}\n", block.prologue(), loc_str.paint(WARN), block.epilogue() ) } else { write!( f, "{}:\n\t{}", loc_str.paint(WARN), self.message.replace('\n', "\n\t") ) } } } #[derive(Debug, thiserror::Error)] pub enum Error { #[error(transparent)] ParseError(Box<ParseError>), #[error("{0}")] IOError(#[from] std::io::Error), } }
As we can see, it either wraps IOError or, for Rustemo generated errors,
provide message, file and location inside the file.