Builders
A builder is a component that is called by the parser during the parsing process to constructs the output.
Currently Rustemo can be configured with three builder types:
-
The default builder
When default builder is used, Rustemo will perform type inference for Abstract-Syntax Tree (AST) node types based on the grammar. The builder, AST types, and actions for creating instances of AST nodes will be generated.
-
Generic tree builder
This builder builds a tree where each node is of
TreeNodetype. -
Custom builder
Is provided by the user.
Default builder
For default builder Rustemo will generate default AST types and actions following a certain set of rules explained in this section. The generated builder will then call into actions to produce instances of the AST types. The final output of this builder is AST tailored for the given grammar.
The builder will be generated, together with the parser, inside <lang>.rs file
where <lang> is the name of the grammar. The actions will be generated into
<lang>_actions.rs file.
There are two approaches where generated files are stored. See the configuration section.
Abstract-Syntax Tree (AST) representation of the input is different from a Concrete-Syntax Tree (CST, aka the Parse Tree). AST represents the essence of the parsed input without the concrete syntax information.
For example, 3 + 2 * 5 represents an algebric expression where we multiply 2
and 5 and then add product to 3. AST should be the same no matter what is
the concrete syntax used to write down this information.
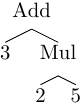
We could write the same expression in the post-fix (Reverse Polish) notation
like 3 2 5 * +. CST would be different but the AST would be the same.
By default, this builder do not store location information in the generated AST
types. This can be changed by builder_loc_info settings.
If this settings is configured then each token and generated struct type is
wrapped in ValLoc
type which provides location field and can be dereferenced to the wrapped
value.
See also loc_info test.
AST type inference
Based on grammar rules Rustemo will infer and generate AST node types which you can modify afterwards to suit your needs, so you can quickly have a working parser and tune it later.
The inference is done by the following rules:
Each non-terminal grammar rule will be of an enum type. The enum variants will
be:
- If only non-content matches are in the production (e.g. just string matches) -> plain variant without inner content
- A single content match (e.g. regex match) or rule reference without assignment -> variant with referred type as its content.
- Multiple content matches and/or assignments -> a
structtype where fields types are of the referred symbols.
In addition, production kinds and assignments LHS names are used for
fields/function/type naming. Also, cycle refs are broken using Box.
Probably the best way to explain is by using an example. For example, if we have the following grammar:
E: left=E '+' right=E {Add, 1, left}
| left=E '-' right=E {Sub, 1, left}
| left=E '*' right=E {Mul, 2, left}
| left=E '/' right=E {Div, 2, left}
| base=E '^' exp=E {Pow, 3, right}
| '(' E ')' {Paren}
| Num {Num};
terminals
Plus: '+';
Sub: '-';
Mul: '*';
Div: '/';
Pow: '^';
LParen: '(';
RParen: ')';
Num: /\d+(\.\d+)?/;
we get these generated actions/types:
#![allow(unused)] fn main() { use super::calculator04_ambig_lhs::{Context, TokenKind}; /// This file is maintained by rustemo but can be modified manually. /// All manual changes will be preserved except non-doc comments. use rustemo::Token as BaseToken; pub type Input = str; pub type Ctx<'i> = Context<'i, Input>; #[allow(dead_code)] pub type Token<'i> = BaseToken<'i, Input, TokenKind>; pub type Num = String; pub fn num(_ctx: &Ctx, token: Token) -> Num { token.value.into() } #[derive(Debug, Clone)] pub struct Add { pub left: Box<E>, pub right: Box<E>, } #[derive(Debug, Clone)] pub struct Sub { pub left: Box<E>, pub right: Box<E>, } #[derive(Debug, Clone)] pub struct Mul { pub left: Box<E>, pub right: Box<E>, } /// ANCHOR: named-matches #[derive(Debug, Clone)] pub struct Div { pub left: Box<E>, pub right: Box<E>, } #[derive(Debug, Clone)] pub struct Pow { pub base: Box<E>, pub exp: Box<E>, } #[derive(Debug, Clone)] pub enum E { Add(Add), Sub(Sub), Mul(Mul), Div(Div), Pow(Pow), Paren(Box<E>), Num(Num), } pub fn e_add(_ctx: &Ctx, left: E, right: E) -> E { E::Add(Add { left: Box::new(left), right: Box::new(right), }) } /// ANCHOR_END: named-matches pub fn e_sub(_ctx: &Ctx, left: E, right: E) -> E { E::Sub(Sub { left: Box::new(left), right: Box::new(right), }) } pub fn e_mul(_ctx: &Ctx, left: E, right: E) -> E { E::Mul(Mul { left: Box::new(left), right: Box::new(right), }) } pub fn e_div(_ctx: &Ctx, left: E, right: E) -> E { E::Div(Div { left: Box::new(left), right: Box::new(right), }) } pub fn e_pow(_ctx: &Ctx, base: E, exp: E) -> E { E::Pow(Pow { base: Box::new(base), exp: Box::new(exp), }) } pub fn e_paren(_ctx: &Ctx, e: E) -> E { E::Paren(Box::new(e)) } pub fn e_num(_ctx: &Ctx, num: Num) -> E { E::Num(num) } }
We see that each grammar rule will have its corresponding type defined. Also, each production and each terminal will have an actions (Rust function) generated. You can change these manually and your manual modifications will be preserved on the next code generation as long as the name is the same.
On each code generation the existing <>_actions.rs file is parsed using syn
crate and each type and action that is missing
in the existing file is regenerated at the end of the file while the existing
items are left untouched. The only items that cannot be preserved are non-doc
comments.
This enables you to regenerate types/actions by just deleting them from the actions file and let rustemo run. If you want to regenerate actions/types from scratch just delete the whole file.
Here is an example of generated and manually modified actions for the same grammar above:
#![allow(unused)] fn main() { use super::calculator04_ambig_lhs::{Context, TokenKind}; /// This file is maintained by rustemo but can be modified manually. /// All manual changes will be preserved except non-doc comments. use rustemo::Token as BaseToken; pub type Input = str; pub type Ctx<'i> = Context<'i, Input>; pub type Token<'i> = BaseToken<'i, Input, TokenKind>; pub type Num = f32; pub fn num(_ctx: &Ctx, token: Token) -> Num { token.value.parse().unwrap() } pub type E = f32; pub fn e_add(_ctx: &Ctx, left: E, right: E) -> E { left + right } pub fn e_sub(_ctx: &Ctx, left: E, right: E) -> E { left - right } pub fn e_mul(_ctx: &Ctx, left: E, right: E) -> E { left * right } pub fn e_div(_ctx: &Ctx, left: E, right: E) -> E { left / right } pub fn e_pow(_ctx: &Ctx, base: E, exp: E) -> E { f32::powf(base, exp) } pub fn e_paren(_ctx: &Ctx, e: E) -> E { e } pub fn e_num(_ctx: &Ctx, num: Num) -> E { num } }
In these actions we are doing actual calculations. For the full explanation see the calculator tutorial.
Lexing context is passed to actions as a first parameter. This can be used to write semantic actions which utilize lexing information like position or surrounding content. For example, layout parser used with string lexer can use this to construct and return a borrowed string slice which span the layout preceding a next valid token. To be able to return a string slice, layout actions need access to the input string and start/end positions.
Generic tree builder
This is a built-in builder that will produce a generic parse tree (a.k.a Concrete-Syntax-Tree (CST)).
For example, given the grammar:
S: A+ B;
A: 'a' Num;
terminals
B: 'b';
Ta: 'a';
Num: /\d+/;
The test:
#![allow(unused)] fn main() { #[test] fn generic_tree() { let result = GenericTreeParser::new().parse("a 42 a 3 b"); output_cmp!( "src/builder/generic_tree/generic_tree.ast", format!("{:#?}", result) ); } }
will produce this output:
Ok(
NonTermNode {
prod: S: A1 B,
span: [0(1,0)-10(1,10)],
children: [
NonTermNode {
prod: A1: A1 A,
span: [0(1,0)-8(1,8)],
children: [
NonTermNode {
prod: A1: A,
span: [0(1,0)-4(1,4)],
children: [
NonTermNode {
prod: A: Ta Num,
span: [0(1,0)-4(1,4)],
children: [
TermNode {
token: Ta("\"a\"" [0(1,0)-1(1,1)]),
layout: None,
},
TermNode {
token: Num("\"42\"" [2(1,2)-4(1,4)]),
layout: Some(
" ",
),
},
],
layout: None,
},
],
layout: None,
},
NonTermNode {
prod: A: Ta Num,
span: [5(1,5)-8(1,8)],
children: [
TermNode {
token: Ta("\"a\"" [5(1,5)-6(1,6)]),
layout: Some(
" ",
),
},
TermNode {
token: Num("\"3\"" [7(1,7)-8(1,8)]),
layout: Some(
" ",
),
},
],
layout: Some(
" ",
),
},
],
layout: None,
},
TermNode {
token: B("\"b\"" [9(1,9)-10(1,10)]),
layout: Some(
" ",
),
},
],
layout: None,
},
)
We can see that we get all the information from the input. Each node in the tree
is a TermNode or NonTermNode variant of TreeNode enum. Each node keeps the
layout that precedes it.
For details see the full test.
Generic builder can be configured by Settings::new().builder_type(BuilderType::Generic)
settings API, exposed through --builder-type generic in the rcomp CLI.
Custom builders
If you have a specific requirement for the build process you can implement a builder from scratch.
To provide a custom builder you start with a type that implements a
rustemo::Builder trait and after that implements a concrete parsing algorithm
trait. Currently, Rustemo is a (G)LR parser thus you can use
rustemo::LRBuilder trait.
Let's see how can we do all of this by implementing a builder that does
on-the-fly calculation of the arithmetic expression. Start with a type and a
base Builder trait implementation as each builder needs initialization and
should be able to return the final result.
To use a custom builder you should generate the parser with --builder-type custom if using rcomp CLI, or calling
rustemo_compiler::Settings::new().builder_type(BuilderType::Custom) if
generating parser from the build.rs script.
For example, given the grammar:
#![allow(unused)] fn main() { E: E '+' E {Add, 1, left} | E '*' E {Mul, 2, left} | Num {Num}; terminals Plus: '+'; Mul: '*'; Num: /\d+/; }
in the file custom_builder.rustemo, the following builder from file
custom_builder_builder.rs will perform arithmetic operation on-the-fly (during
parsing):
#![allow(unused)] fn main() { pub type E = i32; pub type Context<'i> = LRContext<'i, str, State, TokenKind>; /// Custom builder that perform arithmetic operations. pub struct MyCustomBuilder { // A stack used to shift numbers and keep intermediate result stack: Vec<E>, } impl MyCustomBuilder { pub fn new() -> Self { Self { stack: vec![] } } } impl Builder for MyCustomBuilder { // Result of the build process will be a number type Output = E; fn get_result(&mut self) -> Self::Output { assert!(self.stack.len() == 1); self.stack.pop().unwrap() } } }
Now, implement LR part of the builder. For this we must specify what should be
done for shift/reduce operations:
#![allow(unused)] fn main() { impl<'i> LRBuilder<'i, str, Context<'i>, State, ProdKind, TokenKind> for MyCustomBuilder { fn shift_action(&mut self, _context: &Context<'i>, token: Token<'i, str, TokenKind>) { if let TokenKind::Num = token.kind { self.stack.push(token.value.parse().unwrap()) } } fn reduce_action(&mut self, _context: &Context<'i>, prod: ProdKind, _prod_len: usize) { let res = match prod { ProdKind::EAdd => self.stack.pop().unwrap() + self.stack.pop().unwrap(), ProdKind::EMul => self.stack.pop().unwrap() * self.stack.pop().unwrap(), ProdKind::ENum => self.stack.pop().unwrap(), }; self.stack.push(res); } } }
And finally, you call the parser with the instance of custom builder as:
#![allow(unused)] fn main() { let result = CustomBuilderParser::new(MyCustomBuilder::new()).parse("2 + 4 * 5 + 20"); }
You can see the full test here.